
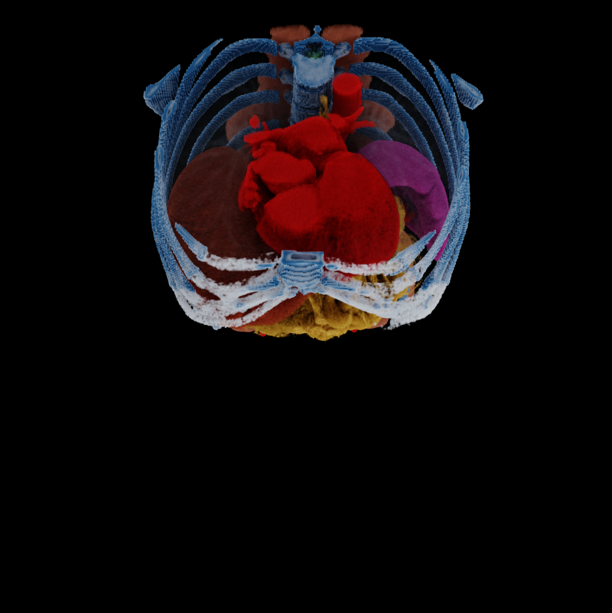
Photorealistic volumetric rendering of CT scans greatly benefits clinical workflows, yet neural approaches such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) require prohibitive per-scan optimization (hours for NeRF, about 30 minutes for 3DGS), making them impractical in clinical settings. We propose Render-FM, a feedforward model that eliminates this bottleneck by directly regressing 6D Gaussian Splatting (6DGS) parameters from a CT volume in a single 2.8-second forward pass, a 500× speedup over per-scan optimization.
To bridge the domain gap between natural scene reconstruction and medical volumetric rendering, we introduce Anatomy-Guided Priming (AGP), which incorporates segmentation masks and transfer functions as structural and appearance priors, information that existing Gaussian splatting methods overlook. Built on an nnU-Net-inspired 3D U-Net trained on diverse CT scans, Render-FM predicts per-voxel 6DGS parameters and supports immediate real-time rendering.
Unlike per-scan methods, Render-FM generalizes to unseen anatomies, novel transfer functions, and enables compositional organ visualization with zero additional preparation time. Optional 89-second fine-tuning further improves quality, surpassing per-scan optimized baselines.
Render-FM runs interactively on a single laptop RTX 2000 Ada GPU.
Comparison on TotalSegmentator (in-domain) and CT-ORG (out-of-domain). Render-FM matches or beats per-scan optimized 6DGS while reducing preparation time by two to three orders of magnitude.
| Setting | Method | SSIM↑ | PSNR↑ | LPIPS↓ | Time↓ |
|---|---|---|---|---|---|
| TotalSeg ID, Seen TF |
6DGS | 0.912 | 26.63 | 0.096 | 1463.9 s |
| 6DGS + AGP (Ours) | 0.925 | 28.92 | 0.093 | 1786.5 s | |
| Render-FM (Ours) | 0.919 | 27.30 | 0.097 | 2.8 s | |
| Render-FM + FT (Ours) | 0.937 | 31.67 | 0.088 | 89.4 s | |
| CT-ORG OOD, Seen TF |
6DGS | 0.903 | 25.97 | 0.105 | 1528.7 s |
| 6DGS + AGP (Ours) | 0.926 | 29.36 | 0.091 | 2261.9 s | |
| Render-FM (Ours) | 0.918 | 26.21 | 0.092 | 2.6 s | |
| Render-FM + FT (Ours) | 0.940 | 32.48 | 0.082 | 136.2 s |
Bold = best in block. Full results (Unseen TF, compositional Skeleton group, CTPelvic1K) are in the paper.
Qualitative comparison of 6DGS 6DGS + AGP (Ours) Render-FM (Ours) Render-FM + FT (Ours) Ground Truth. Drag the dividers to compare. Results are under a sparse-view setting of 20 views for training 6DGS or fine-tuning Render-FM.
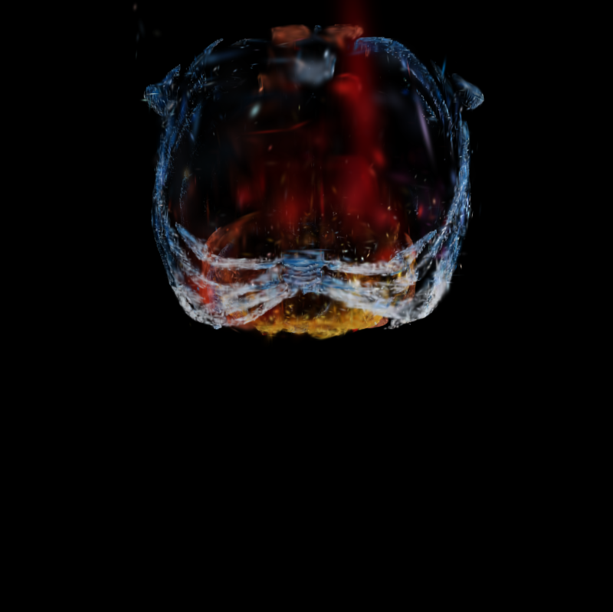
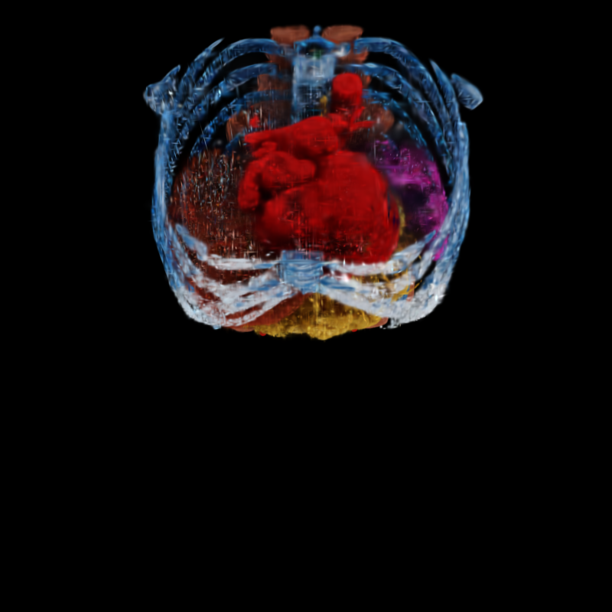
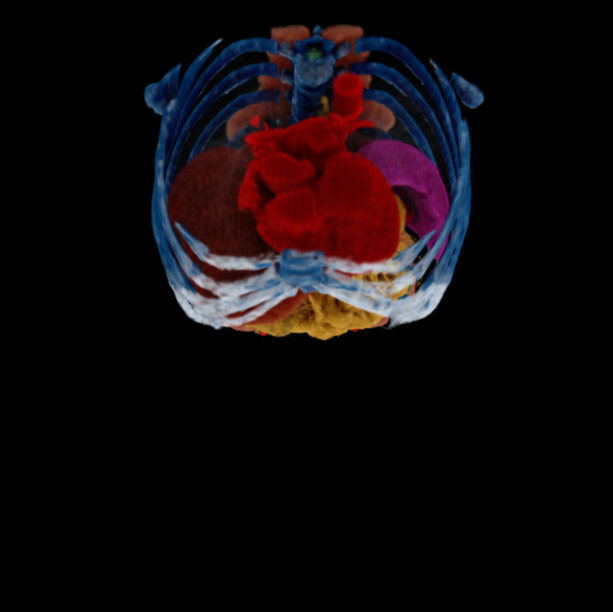
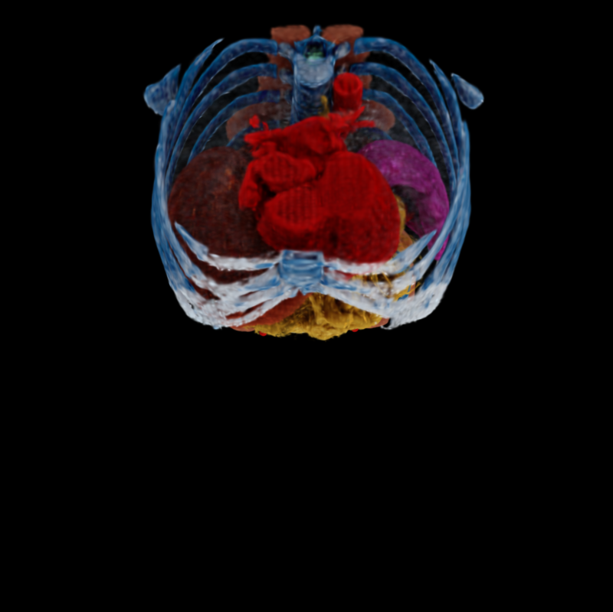
@inproceedings{gao2026renderfm,
title = {Render-FM: Feedforward Model for Real-time Photorealistic Volumetric Rendering},
author = {Gao, Zhongpai and Planche, Benjamin and Zheng, Meng and
Choudhuri, Anwesa and Nguyen, Van Nguyen and Chen, Terrence and Wu, Ziyan},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2026}
}